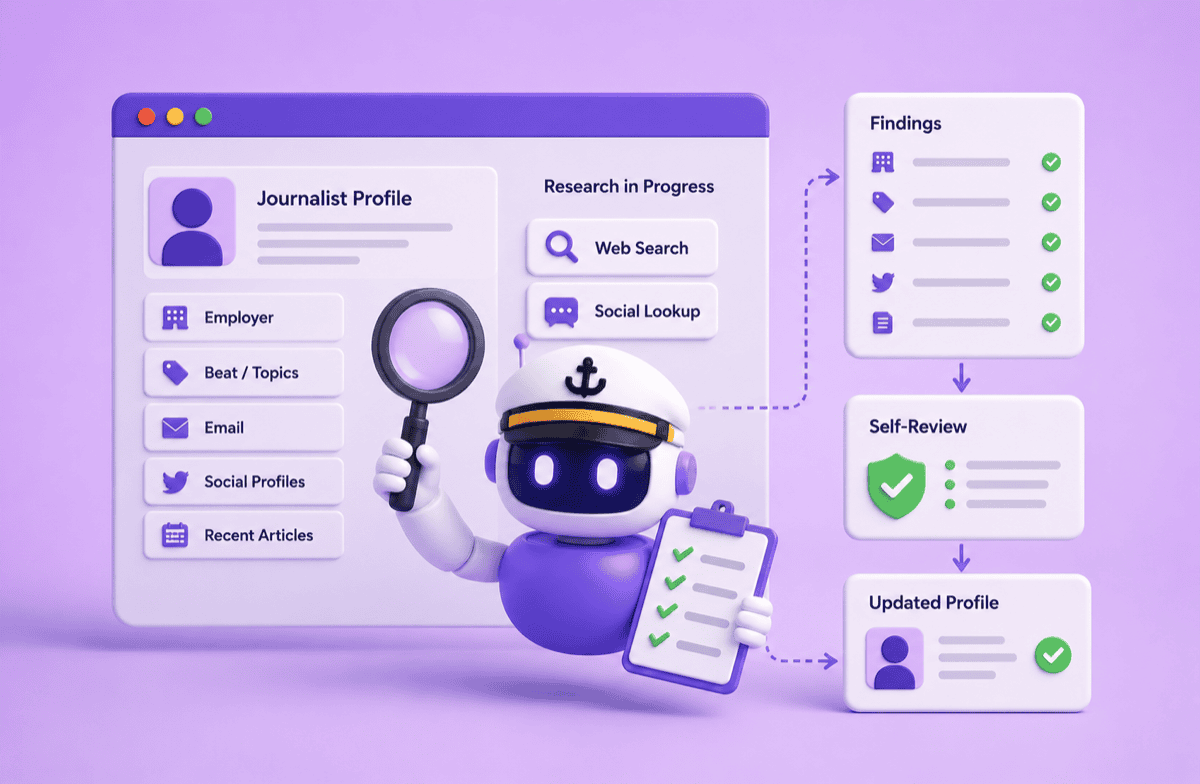
One of Meltwater’s core products is its Media Database, with nearly 1,000,000 journalist and media contact profiles used by PR and communications teams to find the right person for a story. Its value depends on those profiles staying up to date. New journalists need to be created and existing journalists move between outlets, go freelance, and shift their coverage focus. Keeping pace with those changes and maintaining a high-quality, up-to-date database is what our team is after.
For years, maintaining that data was largely a manual process. Human researchers verified employment, updated contact information, confirmed coverage areas, and cross-referenced multiple sources to keep records current. While effective, the process is time-consuming, difficult to scale, and often leads to inconsistencies across researchers.
![]()
In 2025, we built an AI agent to do the majority of this work, which frees up our human researchers to focus on the most complex cases and quality control. The agent’s job is to take a journalist profile, research the latest information about that journalist, and update the profile with any changes it can confirm from relevant sources with high enough confidence. It needs to be able to search the web, interpret results, and make judgments about what information is reliable and relevant.
This is the story of our first media research agent Admiral: what we built, what worked, and what we would (and by now did, stay tuned for part 2) do differently. Running Admiral in production, we were able to reduce research cost by 85% and time spent per profile by 90%, while improving accuracy and coverage of the profiles by 12%. We were able to improve our profiles freshness scores by 24.3% in 2025, a high freshness score means profile metadata is recently confirmed or updated.
The Approach
We started from what a human researcher actually does: search for a journalist’s recent work, check their social profiles, confirm their employer, and write up a structured record.
The agent has access to two tools, web search and social media lookups. Each research round means picking a tool, reading the results, and deciding what to look for next.
Once the agent judges it has gathered enough evidence, it attempts to submit its findings. A separate step then evaluates whether that submission is complete, and sends the agent back with specific instructions if it isn’t.
Those two phases run as a loop:
As a safetynet, to prevent infinite loops, but also to prevent wasting money on a profile for which the information is just not out there, we set a maximum number of research rounds. If the agent hits that limit without being satisfied, it has to submit whatever it has found so far, even if it’s incomplete.
What Worked Well
The self-review step
The self-review step makes a big difference. Without it, the agent has no way to tell when it has missed something. A confident-sounding but incomplete answer looks identical to a thorough one. Adding an explicit evaluation step before accepting any output fixes this.
Plausible-looking but wrong output drops sharply, because the review step catches exactly the thin-evidence cases the agent itself couldn’t detect.
The review prompt, simplified here for illustration, looks something like this:
The research agent is planning to submit the following profile.
Review it carefully and give your reasoning.
Check in particular:
- Is the current employer confirmed from a recent source, not just inferred?
- Are there bylines from the last 6 months that match the listed beat?
- Are the social handles verified as belonging to this specific journalist?
- Is the email address sourced directly, not guessed from a domain pattern?
If the submission is not good enough, be specific: name the exact fields
that need more evidence and suggest what to search for next.
{proposed output}
The reflection response comes back as structured output: A yes/no verdict if the submission is satisfactory, a list of reasons, and (if rejected) specific improvement instructions.
{
"reason": [
"The employer appears in the profile but no recent byline confirms it",
"The email was found but the source is a 2019 staff page - may be outdated"
],
"is_satisfactory": false,
"improvement_instructions": "Search for recent articles by this journalist to confirm current employer. Find a more recent email source."
}
It’s a simple mechanism. The agent can only close a task by convincing a second check that its evidence is solid. That’s what makes the output reliable enough to act on automatically.
Per-field confidence and sources
Every field in the output includes both a confidence score and the evidence used to support it:
{
"email": {
"value": "reporter@outlet.com",
"confidence": 0.9,
"reasoning": "Found on outlet staff page, confirmed in social bio",
"sources": "https://outlet.com/staff/reporter, https://socialmedia.com/reporter/bio"
}
}
Having a confidence score lets us act on findings selectively. Only the highest-confidence fields are applied automatically, while lower-confidence results are routed to a human reviewer, where the agent’s confidence, reasoning, and sources make that review far faster than starting from scratch. Not every field requires the same level of certainty, and confidence gives us a practical way to balance speed with accuracy without ever taking the human fully out of the loop.
Having sources is equally important. When the agent is wrong, we can trace exactly where a piece of information came from and why the model believes it. Without that audit trail, debugging would be guesswork. With it, we can inspect individual decisions, understand failures, and improve the system.
The confidence score also becomes part of the update workflow:
Instead of treating every finding the same, we can make different decisions depending on the quality of the evidence. Strongly supported updates flow through automatically. Ambiguous cases go to a human reviewer. That makes the system both more scalable and easier to trust.
Keeping the toolset small
We didn’t land on a small toolset by design, we landed on it by trying the opposite first.
The intuition was: more sources, more evidence, better answers. So we gave the agent web search plus a handful of third-party APIs that promised structured journalist data. In practice those APIs frequently conflicted with each other and with what the agent found through web search, and a lot of the data was outdated. The agent had no good framework for deciding who to trust, and the task grew complex quickly, especially given the unbounded context window.
Narrowing the toolset to web search and a small set of social media lookups works much better. These are sources we understand, with failures we can reason about. The agent has enough signal to triangulate without spending most of its effort reconciling contradictions it can’t resolve.
We never went back to the broader toolset. The experience reinforced something we kept running into: the agent works best when it has fewer things to weigh up, not more. Every rule we moved outside the loop rather than inside it made the remaining decisions more predictable and the failures easier to trace.
What We’d Do Differently
The context window never shrinks
Each time the agent decides what to do next, it receives the full history of everything it has done so far: every search query, every result, every previous decision. After several research rounds, that context is very long. Most of it is raw search results the agent has already processed and moved on from.
This has real costs. LLMs charge by the token, so a growing context means a more expensive call each round. It also means the model is attending to a lot of noise it no longer needs. On longer research sessions, quality degrades.
Research and output generation are the same job
The agent that decides what to search for next is also the agent that writes its final structured output. But these are two things that can be considered quite different modes of work.
Exploratory research benefits from a model that is open-ended, willing to follow unexpected leads. Producing structured output benefits from a model that is precise and consistent. The same AI with the same instructions, trying to do both at once, means we can’t optimize either independently. Changes that improve research quality risk making the output more variable, and vice versa.
What We Shipped
Admiral ran in production across the full range of profile types: staff reporters at major outlets, freelancers contributing to dozens of publications, broadcasters with minimal online presence. The self-review loop and per-field confidence scoring made it reliable enough to apply most findings automatically. Most profiles were fully researched and ready in under a minute.
We ran on GPT-4.1 for both the research and review steps, this model gives us good results at a high speed, but comes with a higher cost. At scale, cost tracked directly with context length: each additional research round meant a larger prompt and a more expensive request which together with using a pricer model can quickly become unsustainable.
As volume scaled, the architectural problems compounded. The context window kept growing with each research round. One prompt was stretched across two very different jobs. A critical matching step was nearly impossible to tune or debug in isolation. These were design limitations, and they became the starting point for a rebuild.
Wrap Up
Admiral showed that AI agents can genuinely automate complex research tasks that require judgment, not just lookup. Our media database is growing faster and is more up-to-date than ever.
The self-review pattern and per-field confidence scoring were the right foundations. Both survived into the next version.
Building Admiral also confirmed that the constraints we know from building other software apply here too. When research and output generation share a single prompt, you can’t tune either one without affecting the other. When context grows without bound, so do the costs.
We just had to learn some of those lessons by running it, it’s iterative development after all. The solution is not one allmighty prompt and single agent to do everything, but a system of smaller, more focused agents and prompts that can be optimized independently and have clear interfaces between them, an assembly line of agents so to say.
Each step in the process should be kept as simple as possible, with a clear job to do and a clear output to produce. The system as a whole can be more complex, but each piece should be straightforward. And always, anything that can be moved outside, that does not have to be done with an llm call, should not be done via an llm call! Stay lean, anything that does not add context or reasoning value can be dropped from the prompts.
In part two of this series, we show how splitting Admiral into an assembly line of smaller, independently improvable agents widened field coverage and boosted prediction accuracy by a further 10%, at 40% lower cost. Stay tuned!