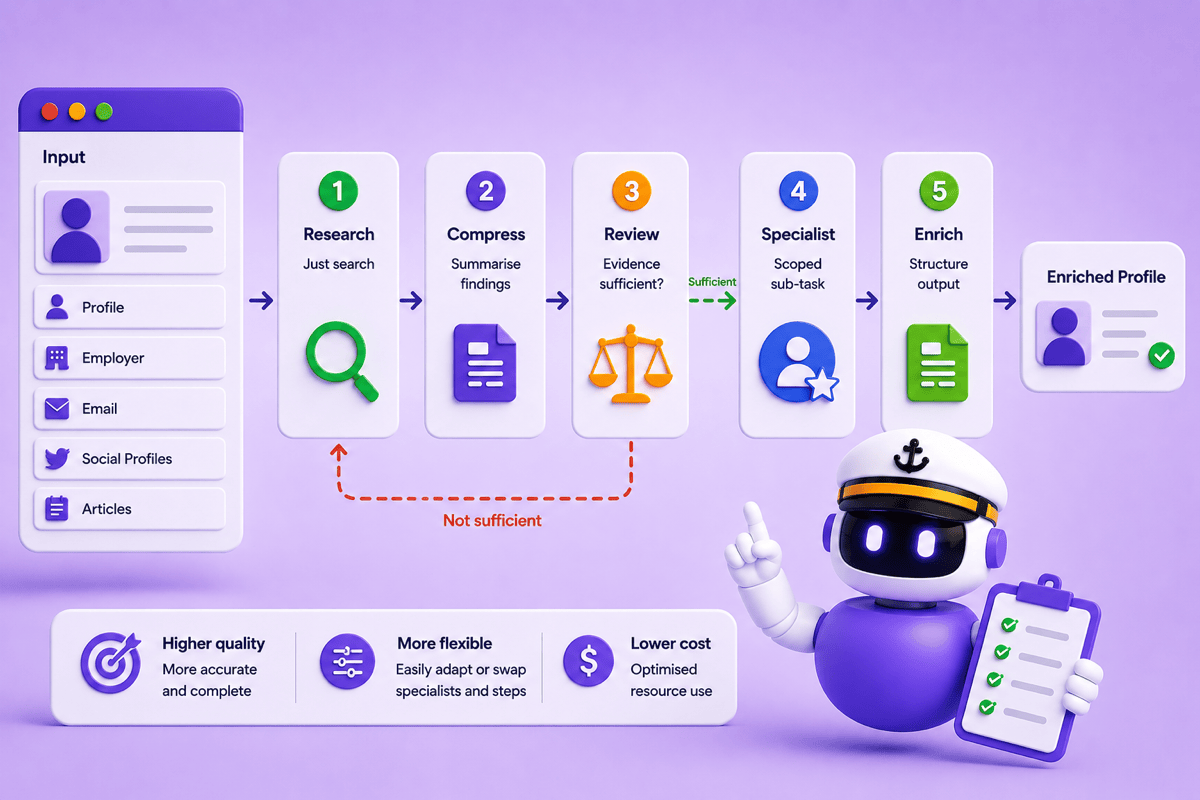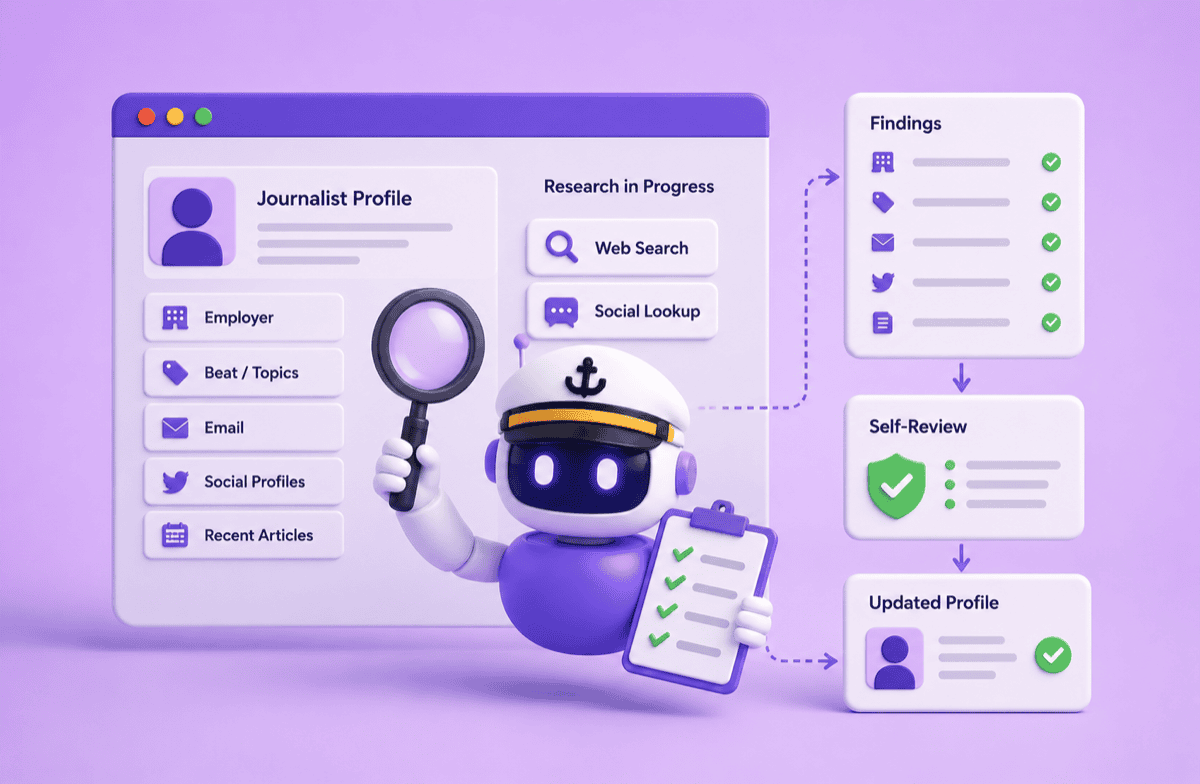
Keeping nearly 1,000,000 journalist profiles accurate used to be a fully manual job. We built an AI agent, Admiral, that cut research cost per profile by 85% and time per profile by 90%. Two lessons did most of the work: the value of a self-review step, and keeping the agent's toolset as...
Featured story
Part 2: Admiral v2 and the Case for Specialist AI Agents
We rebuilt our journalist research pipeline from the ground up, splitting one generalist agent into focused specialist components. The result was 40% lower costs, around 10% higher prediction accuracy, and a system we can finally improve one piece at a time. Read the story