
This is part 5 in our series on how we upgraded our Elasticsearch cluster without any downtime and with minimal user impact.
Due to the large scope of this upgrade, it was clear from the beginning that this project was going to last for at least one year, if not more. This blog post describes how we reasoned about our development process and how we managed to support multiple Elasticsearch client libraries in our Java code bases for a long time.
Supporting multiple Elasticsearch clients
We have several components that interact directly with Elasticsearch. For example, we have a component that is responsible for handling searches and another one that handles indexing. Pretty much all of our deployable components are Docker containers, usually implemented using Java, Kotlin, and Spring Boot.
As we’ve mentioned in one of the previous blog posts, we ran two clusters in parallel with different versions. This meant that all our components needed to somehow support two versions of Elasticsearch until the whole upgrade was completed.
An easy way to achieve this would have been to just stop developing any new features for the old version, effectively a feature freeze, and just continue improving on the new one. However, as the project would continue for years, this was not really an option for us, so we had to find another way.
Guiding principles for development
To allow our team to continue with normal feature delivery to the existing system we decided on some guiding principles that we wanted to stick to during the upgrade.
Always deploy the main branch. We didn’t want to pin any versions because that would stop us from delivering new features. Also, we wanted to avoid long-lived forks and feature branches as it would require us to keep two code bases up to date for every change.
Only have one deployable artifact per component. We wanted to use a feature flag to determine which Elasticsearch version to use. The feature flag would be toggled by an environment variable.
Run the same set of integration tests towards both Elasticsearch versions. By doing this, we would make sure we were backwards compatible. For the small number of cases where we consciously changed our APIs we added specialized tests, highlighting the differences between the versions.
But deciding what we wanted to do, versus actually achieving it, are two different things. Some reasons that made it harder than expected were:
The Elasticsearch API for the two versions we changed between was not compatible.
Our old, custom Elasticsearch version was only compatible with Java 8, so we could not take advantage of Java modules.
The (transport) client API used in early versions of Elasticsearch requires the entire Elasticsearch dependency tree to be present in the Java classpath. This means that running two versions of the client at the same time, in the same JVM, results in classpath conflicts.
Solving the classpath conflicts
As the two Elasticsearch APIs weren’t compatible with each other we needed both versions of the API libraries loaded into the runtime of all components that interacted with elasticsearch.
We looked into various alternatives on how to solve this, for example using separate class loaders or building two variants of every component with different sets of dependencies.
After some extensive research, we ended up using the Gradle shadow plugin. Amongst several things, that plugin can relocate classes to use different package names than they had to begin with. For example, the class TermQueryBuilder, located in the package “org.elasticsearch.index.query”, exists in both Elasticsearch versions, but with a different API and implementation. The shadow plugin could then be used to both change the name of the package to “v1.org.elasticsearch.index.query” for the old version of the class, as well as update all imports and references in all other classes that used it. And in this way we could have two variants of the “same” class loaded into the same JVM classpath, but with different package names.
Using the different versions
Once we had a solution for putting both Elasticsearch client APIs on the same classpath we wanted to make it seamless to use them in the rest of our code.
To achieve this, we created our own wrapper library and a client interface on top of the Elasticsearch API. We were very pragmatic here, wrapping only the parts of the API that we were actually using in our components. We made two implementations of the client interface, one for each Elasticsearch version. Roughly it looked like this:
interface ESClient {
fun search(request: ESSearchRequest): ESSearchResult
// … index, scroll, etc
}
class ESClient1: ESClient {
override fun search(request: ESSearchRequest): ESSearchResult {
// Implementation of the old version using the shadowed packages
}
}
class ESClient7: ESClient {
override fun search(request: ESSearchRequest): ESSearchResult {
// Implementation of the new version
}
}
The input and the output from this wrapper client are then version-agnostic wrapper classes that have no dependency on any Elasticsearch API classes, allowing the caller of this code to not know anything about the underlying API version.
By using this client abstraction all of our components could have the same code to make Elasticsearch calls, and it would be version-independent. Which concrete implementation of our wrapper API to use is determined by an environment variable set during component start-up. The setup of one of our components can be seen in Figure 1.
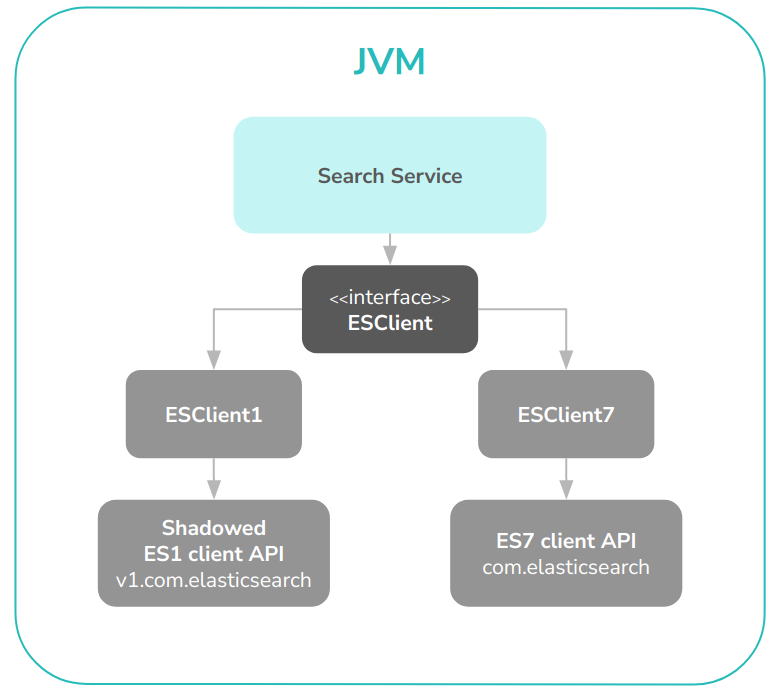
Figure 1. A diagram of how our search component used both elasticsearch client APIs.
This way of working allowed us great flexibility during unit and integration testing. We could reuse all the existing tests we had developed for the old version and run them again towards the new, ensuring backwards compatibility.
Post-upgrade reflections on our approach
There were some pains in our approach. The first one was that we had to change lots of code in several repositories to make them use our client wrapper, which took a lot of time. We also had to spend quite a bit of time trying to get the Shadow plugin to do exactly what we wanted.
But once we had that set up we felt that the described approach worked out really well. It was easy to continue developing new features and we only had one place to change. Once we were done, it was also easy to remove the old code as we only had to remove our wrapper client for the old version, and that’s pretty much it!
This concludes the fifth part of our blog post series on how we upgraded our Elasticsearch cluster. Stay tuned for the next post that will be published sometime next week.
To keep up-to-date, please follow us on Twitter or Instagram.
Up next: Testing & Rollout strategy
Previous blog posts in this series: