At Meltwater we use RabbitMQ for messaging. We have several clusters and had a need for a new cluster. This made us ask the question: how is the message rate affected by the hardware chosen for the cluster? Should we go for more CPU cores? Or maybe faster disks? Are there other things to consider to get the best performance out of RabbitMQ? This blog post tries to answer those questions.
TL;DR Increasing the number of CPU cores or increasing the disk speed has only a limited impact on the throughput of a RabbitMQ cluster with HA queues and persistent messages. All queues should have the same node as master, and all publishers and consumers should connect to the queue master node for best performance.
Test setup
To be able to quickly set up a test environment, we chose to set up the tests on AWS EC2, using different instance types. The instance types used can be seen in the table below. The network performance between the cluster nodes was measured using iperf.
| Instance type | CPU cores | Hyper-threads | CPU speed (MHz) | Memory (GB) | Network (Gbit/s) |
|---|---|---|---|---|---|
| r3.xlarge | 2 | 4 | 2500 | 30.5 | 1.0 |
| r3.2xlarge | 4 | 8 | 2500 | 64 | 1.1 |
| r3.4xlarge | 8 | 16 | 2500 | 128 | 2.2 |
| c3.2xlarge | 4 | 8 | 2900 | 15 | 1.1 |

In all tests, we used two instances of the same instance type to build a RabbitMQ cluster. For generating load, we used a r3.2xlarge instance running the RabbitMQ Java client PerfTest tool. For all tests, SSD instance storage was used.
In all tests, the test queues were using HA mode, and all messages were persisted. In the tests with one queue, there were 10 producers and 10 consumers on that queue. In the tests with 10, 20 and 30 queues, there was one producer and one consumer per queue. All message rates below are messages per second over all queues. Other test properties can be seen in the table below.
| Test property | Value |
|---|---|
| RabbitMQ version | 3.6.5 |
| Erlang version | 19 |
| CentOS version | 7 |
| Test time | 60 s |
| Message size | 4000 B |
Adding CPU cores
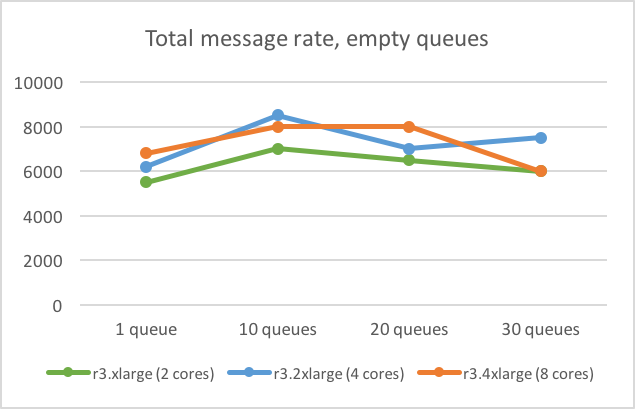
To determine how the performance varied with the number of cores, we tested three different instance types with 2, 4 and 8 CPU cores, each with 2 hyper-threads (r3.xlarge, r3.2xlarge and r3.4xlarge).
The performance improvements were modest when doubling the number of cores. When going from 2 to 4 cores, the message rate increased by only 13% (from 5500 to 6200) in a test with one queue. Doubling the number of cores again from 4 to 8, the message rate increased by only 10% (from 6200 to 6800). Similar results were found in tests with 10, 20 and 30 queues. In some cases, the performance was worse with more cores, as can be seen in the figure below.
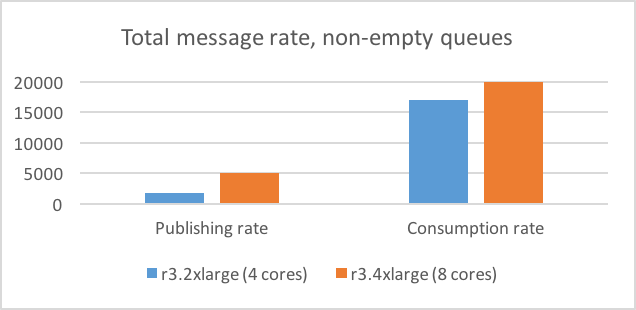
To be able to determine how RabbitMQ would perform in a situation where the consumers were not able to keep up, we also ran a test where 10 queues had 500,000 messages in them when the test started. When doubling the number of cores (from 4 to 8) the publishing message rate more than doubled (from 1750 to 5000) and consumption message rate increased by about 10% (from 17,000 to 20,000), see figure below. In other words, it seems that the number of CPU cores has a larger impact on performance when queues are large than when queues are empty.
Increasing CPU speed
Another question we had was how CPU speed would affect the message rate. Therefore, we compared r3 instances using 2500 MHz CPUs with c3 instances using 2900 MHz CPUs. The test results on c3.2xlarge instances with 4 faster CPU cores were similar to the results of the r3.4xlarge instances with 8 slower CPU cores, i.e. no large impact on performance.
Increasing disk performance
We wanted to know if an increased disk speed would affect performance. We therefore set up two clusters with c3.2xlarge instances. In one of the clusters, we only used one of the two 80 GB SSD disks. In the other cluster, we set up RAID 0 using the two SSD disks, to get better write and read performance. The write-speed increased by 60% from 800MB/s to 1.3GB/s.
The performance increase of the RabbitMQ cluster was modest also in this case. With one queue the message rate increased by 5% (from 6600 to 6900). With 10 queues the increase was also 5% (from 9000 to 9500).
Increasing network performance
To test how the message rate was affected by the network performance we tested both with different latencies and different network throughputs between nodes. The latency within an AWS availability zone is smaller than between zones. Having the cluster nodes in the same availability zone or in different zones showed no significant difference in our tests. To see if the network throughput between the cluster nodes was the bottleneck, we used instance types with different bandwidth. In our test, r3.4xlarge had twice the network throughput compared to the r3.2xlarge instance, but the message rate was similar, as can be seen in the first graph.
Where to connect?
As has been observed by others, the message rate is a lot better if the publishers and consumers connect to the master node of the queue. In our tests, the message rate more than halved (from 6200 to 3000) in a test with one queue, and the message rate decreased by 40% (from 8000 to 5000) in a test with 10 queues. The message rates are worse in any configuration where consumers or publishers connect to the queue slave node.
Spreading the load
Finally, we wanted to know if the performance would increase if the load was spread over the two nodes by dividing the queues evenly between the nodes. Producers and consumers then connected to the queue master node. In a test with 30 queues the message rate decreased by 20% (from 7500 to 6000).
Summary
If you have a RabbitMQ cluster with HA queues and persistent messages, the following applies:
- Doubling the number of CPU cores has a larger impact on throughput when queues are large.
- Improving the disk write speed by configuring RAID 0 only improves the message rate marginally.
- When connecting to a queue slave node, message rates can in the worst case be halved.
- Spreading the load by distributing queues and connections to both cluster nodes decreases performance.