

At Meltwater, we crawl hundreds of thousands of sources to provide real-time insights from over a billion articles every day. However, different from classical “grab everything” crawlers like Googlebot, Meltwater’s crawlers are highly targeted, aiming to surgically crawl only news and other information crucial for PR professionals. That allows us to maximize freshness while minimizing noise, and keeping things affordable.
One of the most persistent challenges in targeted web-scale crawling is knowing the best places to start from. Most targeted crawlers begin from a small set of entry URLs (often called seeds) and discover the rest of the site by following links. If those starting points are poorly chosen, the crawler wastes requests on redundant pages, misses important sections, and becomes slower at finding new content.
The Seed Selection Problem
Historically, seed selection has often been a supervised process: humans or external metadata from, e.g., web directories, firmographic databases, or LLMs are used to identify a homepage and optionally a few section pages for a publication, company, or other news source. That can work at a small scale, but neither humans nor external metadata are particularly good at determining a comprehensive and minimal set of seed URLs. Worse, websites evolve constantly, and a seed set that looked correct yesterday may become inefficient today.
To address this, we built URLBank, a data-driven system that automatically discovers and continuously optimizes the best entry points for crawling, using signals extracted from how links change over time.
We're excited to share that the research behind URLBank, developed in collaboration with Roma Tre University, has been accepted to The ACM Web Conference (WWW) 2026, one of the most competitive venues for applied web research.
Why Seed Management Breaks
A seed set is one of the most important inputs to a targeted crawler. It determines what parts of a site are explored early, what gets revisited often, and ultimately what content gets discovered at all, in particular, when paired with typical limits on crawling depth or volume.
But manual seed selection has three major weaknesses:
It is based on experience and intuition rather than measurable evidence. Even experienced humans cannot reliably predict which pages will consistently surface the most recent content.
External databases or LLMs that provide information about publication, company, or other homepages are targeted to humans and often do not suffice to determine a comprehensive and minimal seed set to cover a full website.
Websites are not stable. Navigation menus, category structures, and internal linking patterns change frequently. This means a static seed set becomes outdated over time, leading to wasted crawl budget and reduced freshness.
At scale, this becomes a systematic problem: you need a way to continuously measure whether a seed set is still good, and automatically improve it when it is not.
The Innovation: Listening to Temporal Signals
URLBank treats seed selection as a resource allocation problem. Instead of assuming which pages are important, it listens to the “heartbeat” of a website by observing how the site evolves over time.
The key idea is simple: a site’s structure is not static. Links appear, disappear, and shift as new articles are published, categories evolve, and navigation menus change. By observing these changes over repeated crawl cycles, URLBank builds temporal link graphs and extracts two site-agnostic signals:
Stability: How persistent is a link across crawl cycles? Links that consistently appear are often structural navigation links, making them strong seed candidates. Links that disappear quickly are more likely short-lived articles.
Productivity: How much new content does a page surface each time we visit? This allows us to prioritize high-yield hubs over redundant entry points.
A Continuous Optimization Loop

URLBank is a continuous, versioned loop integrated directly into our production pipeline. The system operates in three phases:
Expansion → Discover the structure. Starting from a single site URL (or known start URLs), the system crawls to discover the site’s structure. It uses Stability to find structural links, effectively mapping out the site’s skeleton.
Profiling → Measure yield. We monitor these candidate seeds over days or weeks to measure their Productivity, quantifying how many first-seen publications each one contributes over time.
Selection → Optimize under budget. Finally, URLBank uses a greedy algorithm to select the optimal set of seeds that maximizes coverage and content freshness under a strict request budget. This ensures we don’t waste crawl resources on redundant sections that repeatedly surface the same content.
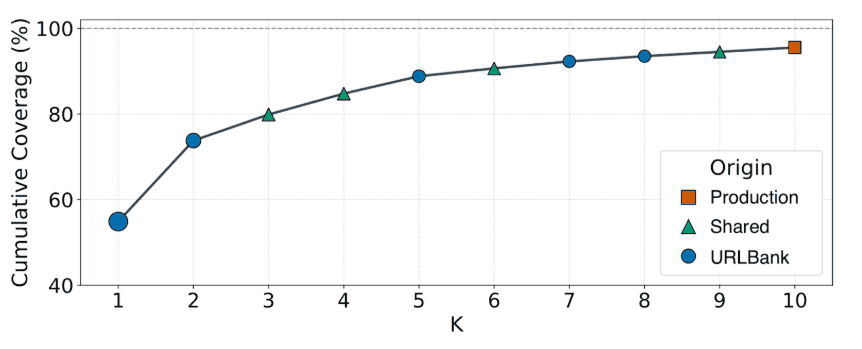
Results: Efficiency at Scale
We evaluated URLBank in a shadow A/B setup across 5,000 sources, covering both high-traffic and long-tail domains.
Under identical crawl conditions, URLBank consistently improved both coverage and freshness, while reducing redundant crawling by selecting smaller, more effective seed sets.
Deployed as a companion system to the crawling pipeline, URLBank has already demonstrated substantial gains in coverage and freshness.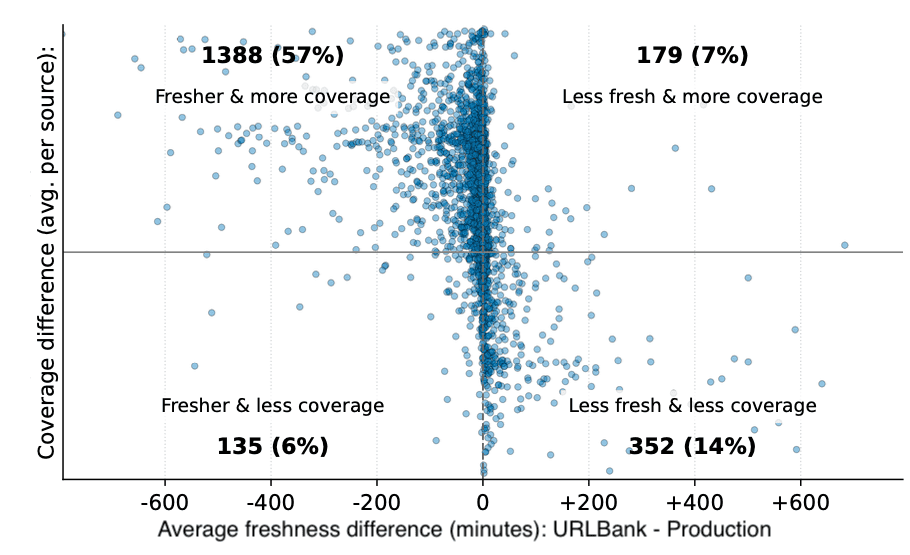
Looking Ahead
URLBank is a step toward making web-scale crawling more adaptive and auditable. Instead of relying on manual updates, we can now continuously learn from crawl behavior and automatically adjust entry points as websites evolve.
We look forward to presenting URLBank at WWW 2026, and continuing to push toward more automated systems for efficient web data extraction.
For a deeper dive, watch our short technical summary video:
This blog post was written by humans. AI was used to generate the illustrations and video above.