At Meltwater we are providing our customers with great tools to analyse news and social media, unlocking business critical insights. However all of this content is written text. Therefore some other forms of media remain unconquered. Formats that are becoming increasingly dominant in all online media. Today, we want to present our plan to conquer audio and video.
The challenges that come with image/video understanding are immense. Extracting information from them can be very hard, and very expensive in terms of time and processing power needed.

From http://contentmarketinginstitute.com
Speech Recognition has its own challenges and is by no means a trivial thing to perform with a computer either. Just to give you a glimpse, try reading these phrases to a friend in a noisy environment:
It’s not easy to wreck a nice beach.
It’s not easy to recognize speech.
It’s not easy to wreck an ice beach.
However, we in the Data Science Research (DSR) team at Meltwater decided to utilize some of the best state-of-the-art speech recognition technologies out there to attempt a short-cut. Our idea was to transcribe the speech in videos, and then run our enrichments on these transcriptions. That way we get sentiment analysis, concepts, named entities, keyphrases and categorizations for free! Basically treating videos like documents in our pipeline.
And that is what we did. As a test, we used google’s speech recognition API to transcribe some youtube videos, however, any other speech recognition system can be used (e.g. [1] or [2]). Our pipeline was successful in producing an enriched document that contained all our enrichments such as Named Entities, Concepts, Keyphrases and Sentiment.
There is an obvious and limiting attribute of videos that makes it difficult to treat them (even conceptually) as text documents; you don’t “see” the whole content at once and can’t “jump” to any point in the content as you do with written text. We wanted a better user experience, so we came up with a new widget that helps the user navigate inside the video itself, to the second where a Named Entity, a Concept or a Keyphrase was uttered in the video. This can be seen in Picture 1.
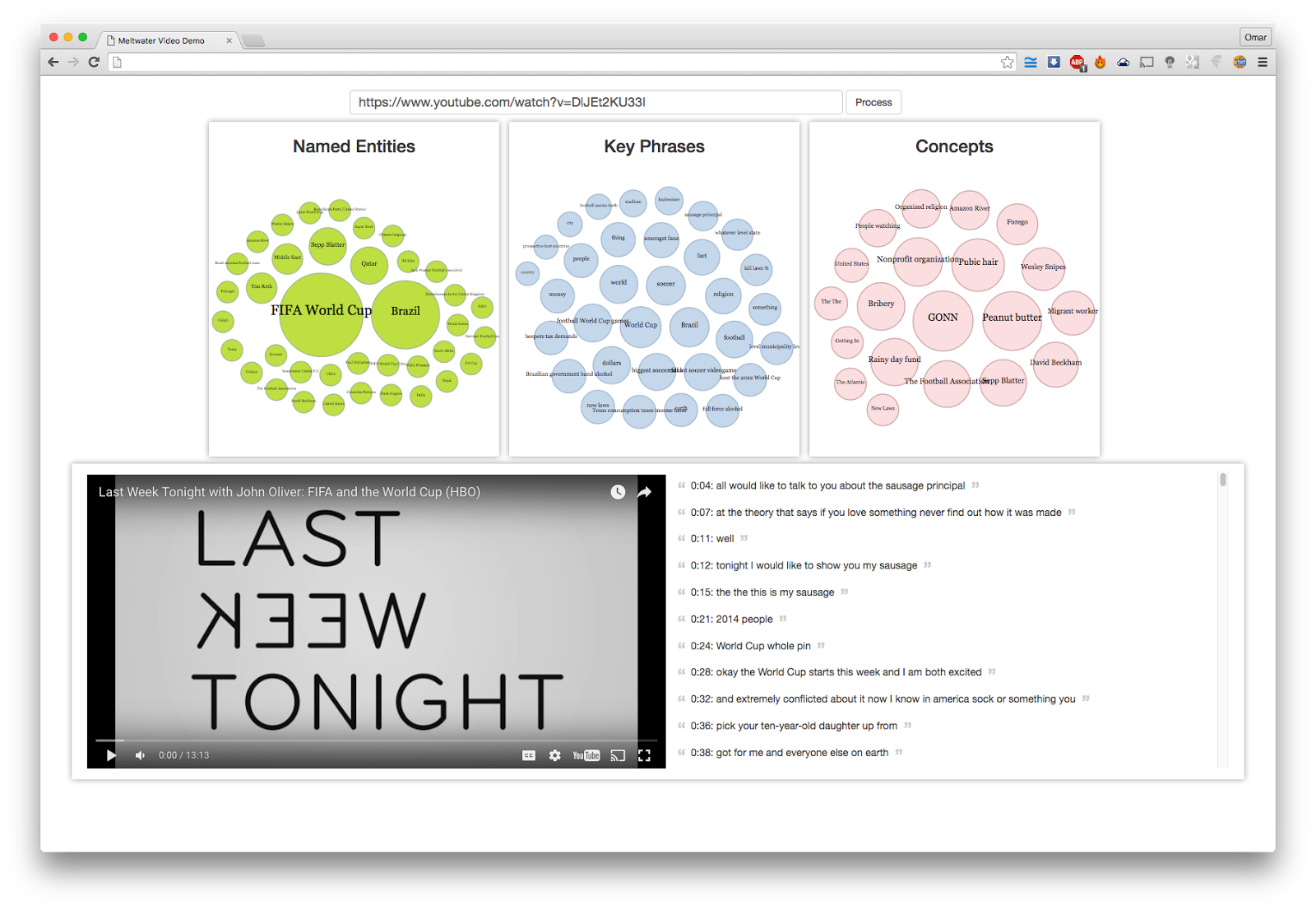
Picture 1: Screenshot of the new video widget.
This screenshot shows the “speech recognition exploration widget” created for this video. We have 3 bubble charts for Named Entities, Keyphrases and Concepts, and a display of video next to its transcript. Once a bubble is clicked, the subtitles which have occurrences of that Named Entity, or Keyphrase or Concept is highlighted and shown, as seen in this Picture 2.
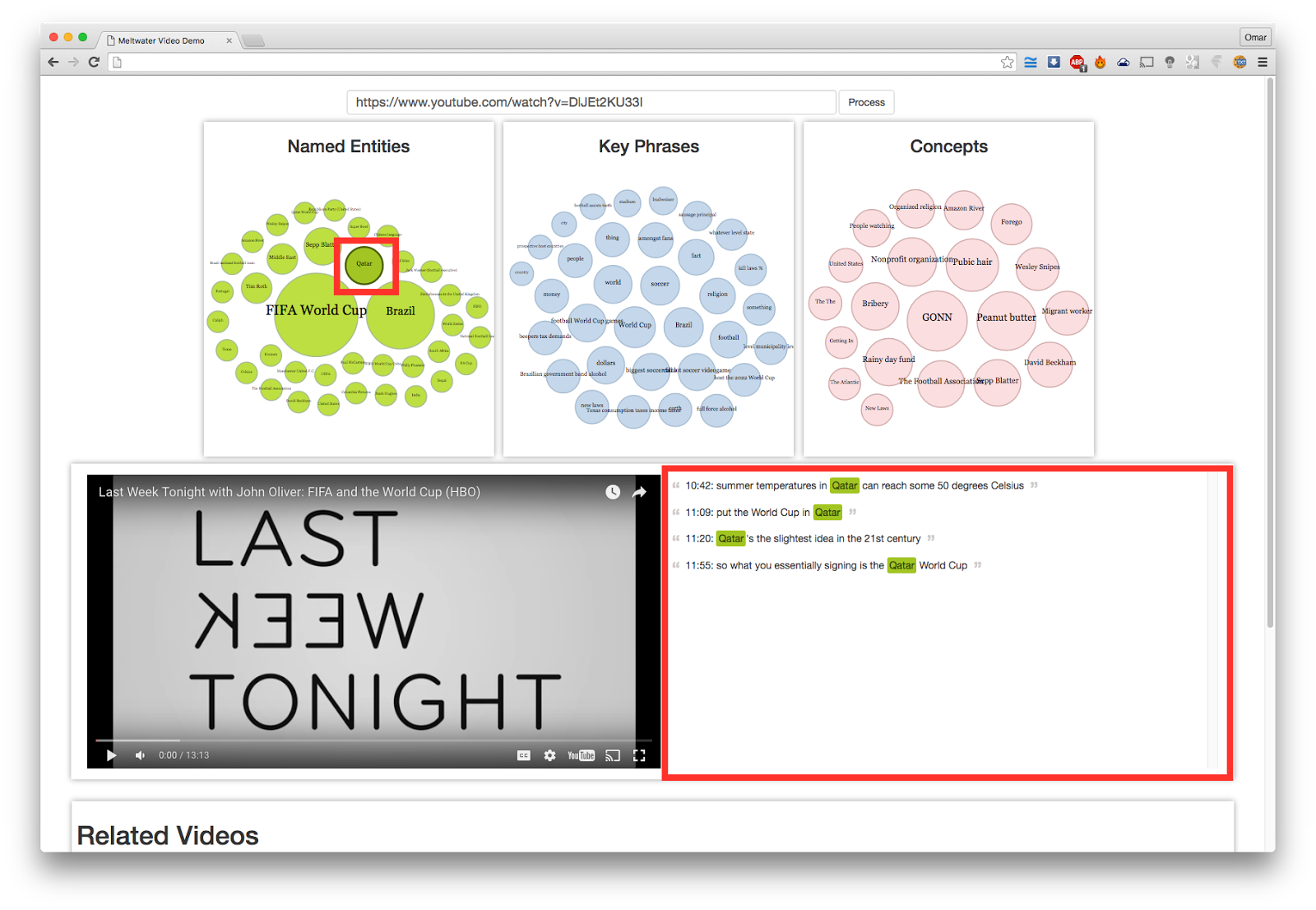
Picture 2: Screenshot showing how selecting “Qatar” in Named Entities filters the transcript.
If multiple selections are made, all the sentences relevant to that selection are highlighted as well, as seen in Picture 3.
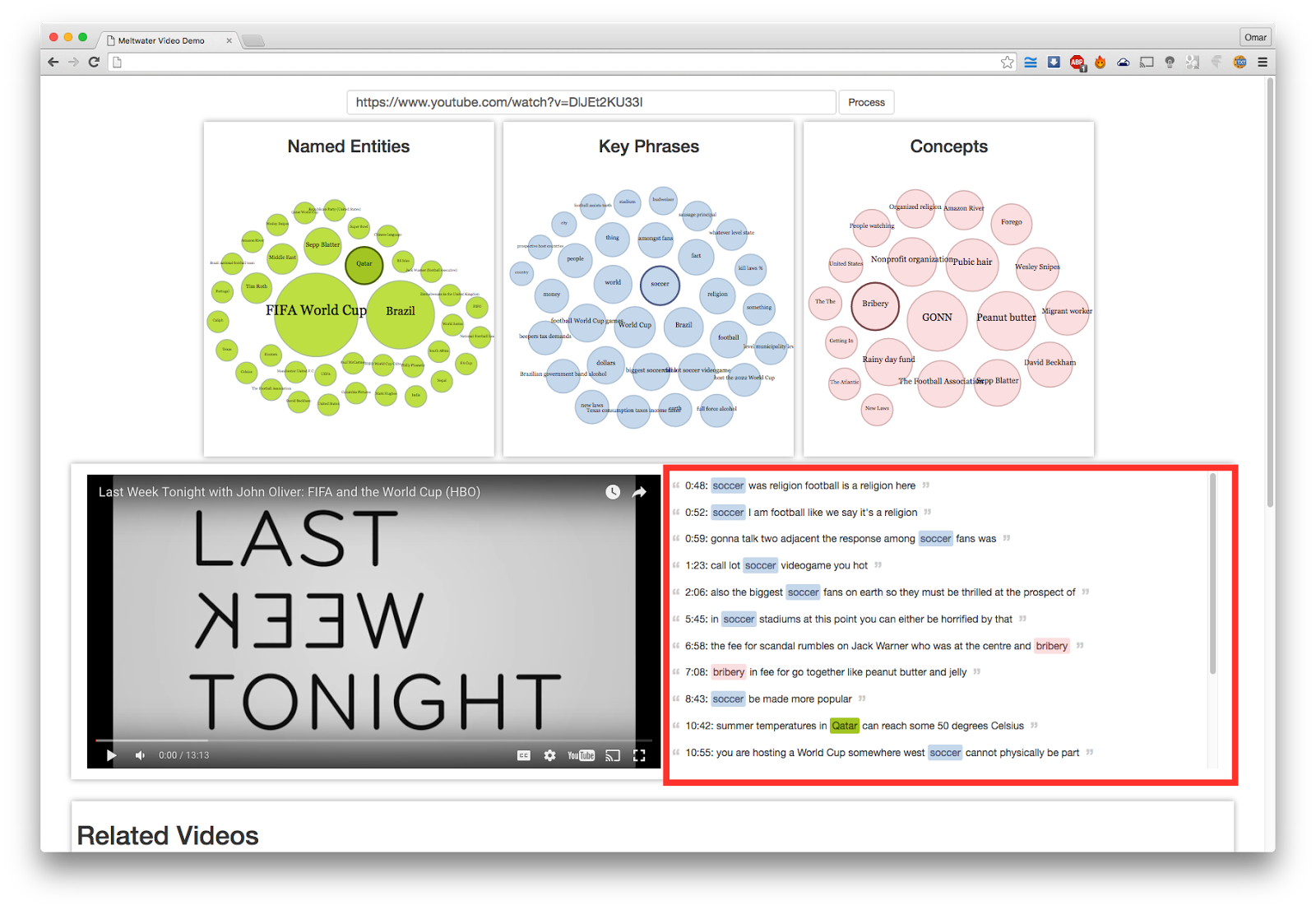
Picture 3: Screenshot showing how selecting multiple bubbles (“Qatar”, “Soccer” and “Bribery) in different charts filters the transcript while highlighting the selection.
Every sentence in the transcript is clickable, so, if the user clicks any of them, they go to that point in the video. This can be seen in Picture 4.

Picture 4: Screenshot showing how clicking a sentence in the transcript seeks the video to the corresponding second when that sentence was uttered.
Finally, we have a section of related videos that are retrieved based on the user’s current selection of bubbles. So, if the user selects “Qatar”, “Soccer” and “Bribery”, they get videos related to that. This is done by indexing the enriched document into cloudsearch (similar to elastic search), and building a search query from the user’s selection. This can be seen in Picture 5.
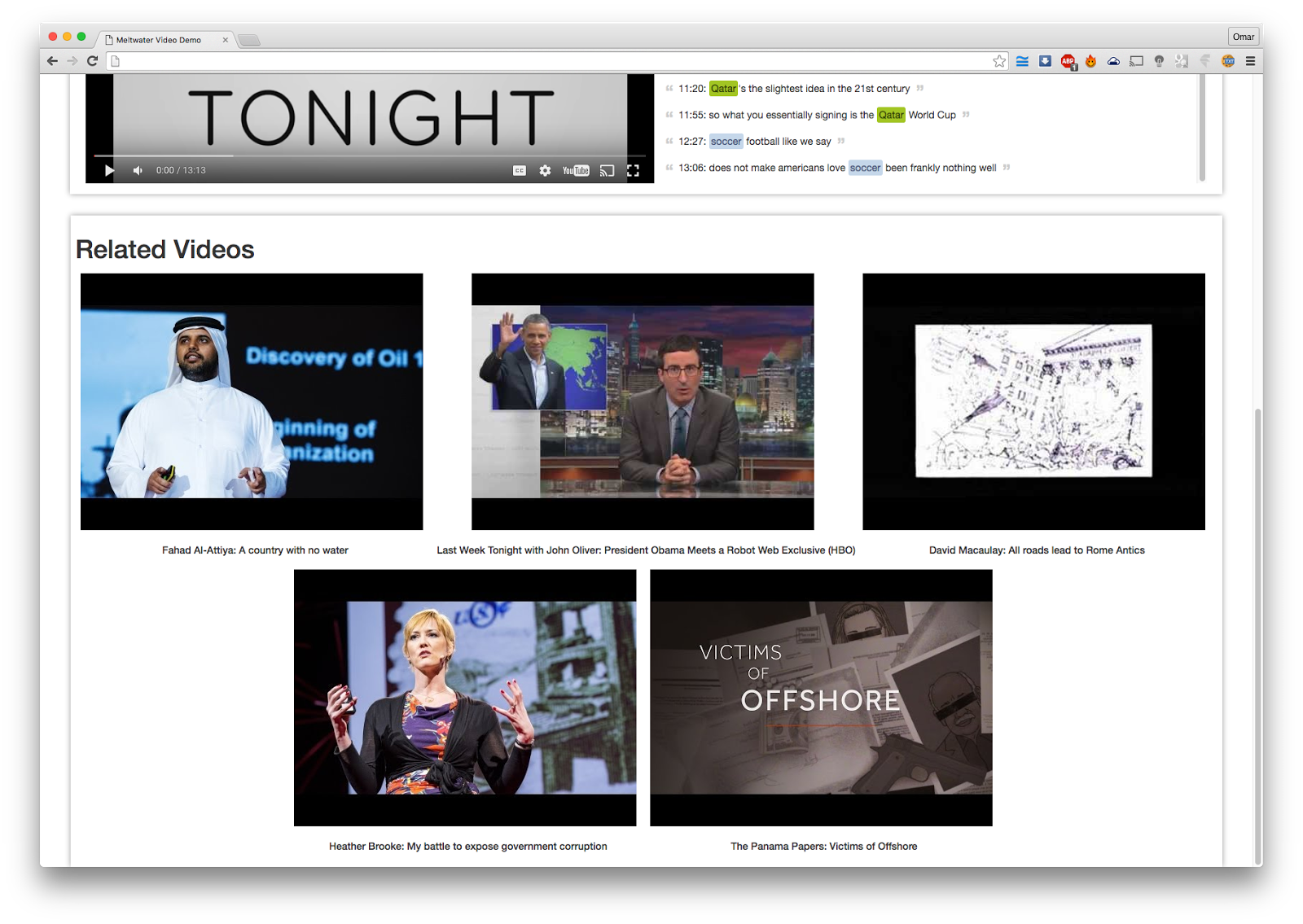
Picture 5: Screenshot showing the related video based on the current bubble selection (“Qatar”, “Soccer”, “Bribe”).
Here a demo video of the widget in action: https://youtu.be/akUPLHeUgHM
Future work:
- Integrate a sample feed of (transcripted) videos into Meltwater’s Platform so we can see how existing widgets can be used.
- Build a widget with a new concept for interactive video exploration.
- Build more models and enrichments specific to handling video transcripts such as:
- Post-processing to correct some mistakes in transcripts
- Building models that accounts for discontinuities in the transcripts, such as a dialogue between different people.
We would love to hear your feedback. Let us know in the comments section any ideas you might have about using video transcription in any application you are interested in.
This is the first in a series of Data Science Research (DSR) related posts that the DSR team at Meltwater will be publishing. The purpose is to increase transparency and visibility into the projects of DSR at Meltwater, and to make the fruits of our strategic research available to the rest of Meltwater engineers, and Data Scientists worldwide.