Backend engineer Yury Smolsky explains how he built Meerkat. Meerkat is an alerting software, developed by Meltwater, that integrates tightly with Graphite.
The Problem

At the end of 2013 our team got tasked to improve the way we throttle our data fetches that are retrieving data from twitter.
It is almost impossible, or at least very costly, to get all tweets from Twitter, as you have to pay for every single tweet. What we can do however is to specify which tweets we are interested in. For that we use the query of our customers and pass them as filters to our data providers. Our data providers will then filter the tweet stream and provide us with all tweets matching the filter. The customer subscribes, with a so-called subscription, to the data that he is interested in.
Unfortunately some of those subscriptions are too vague and they pull too much data, e.g. a search for a punctuation (like a dot). To limit the damage a customer can do, we set a per customer limit on the maximum amount of tweets he can receive in a given period of time, for example 5000 tweets/24h.
Our current approach is to store all data in Graphite, one graph per customer, and to check in regular intervals whether a customer is pulling too much data. Graphite is great, and it can handle a lot of calls, but it also has its limits:
- some subscriptions pull thousands of tweets per minute, so we would have to have a very short interval between calls in order to throttle expensive subscriptions fast enough
- with several thousand subscriptions this creates a huge load on Graphite, more than it can actually handle
Can we fix it?
The diagram below visualizes our current approach.
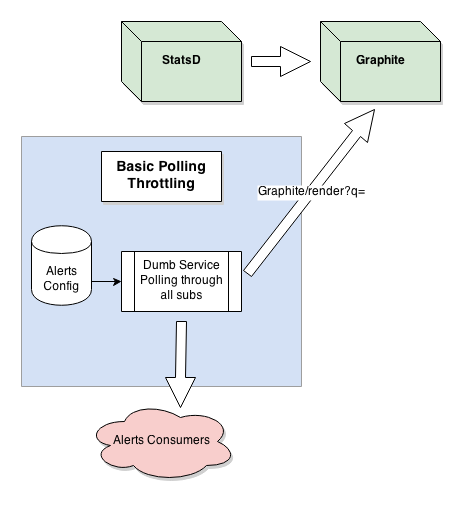
Architecturally, the most obvious place to implement a smarter throttling approach would be to modify Graphite to track down numbers and trigger alerts. Unfortunately it turned out that Graphite is not suited for such modification, as it does not allow any 3rd party plug-ins. Moreover, the authors of Graphite have no intentions to add alerting functionality, as they want to keep Graphite focused on displaying nice graphs in real time, which it does really well with it’s round-robin database.
Therefore we realized that we would have to build a custom solution for this problem. We named our solution Meerkat, as that animal is always on the alert!
We started by analysing the data flow for subscriptions. Not all subscriptions receive new tweets at the same time. Also, some subscription do not accumulate enough tweets so a check would be necessary. Thus checking all subscriptions all the time is unnecessary! What if we could capture data in a separate stream and poll Graphite only if it is really required? Then we could build a system like outlined below, where Meerkat receives data from StatsD and decides what to do with it on his own.
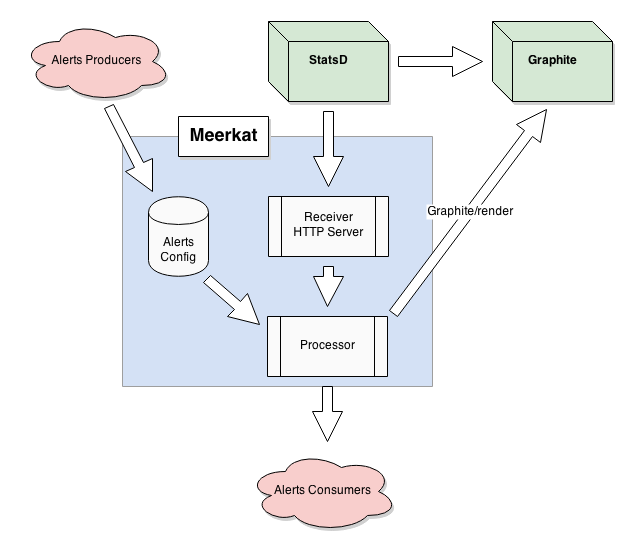
Meerkat would receive metrics from StatsD and store these for a few minutes. Since Graphite has efficient storage mechanisms, we can use it to evaluate alert triggers for a long period of time. Thus, Meerkat should be a simple alerting software attached to Graphite DB API.
We defined our alerts specification as follows:
Alerts can be created with specific condition: reaching high water mark for some metric. Alerts are checked every 30 seconds, which is the interval in which we send the metrics from StatsD to Graphite. Meerkat checks the name of the metric it has received and polls Graphite for the period specified in the alert. When an alert is triggered, Meerkat sends a notification to the specified endpoint, which can be an HTTP call, email, or chat message.
Meerkat does not store any data except a data snapshot of the last minutes. It needs that data to determine whether to pull more data from Graphite.
Assuming a user creates an alert with condition for the metric XYZ with high water mark of 1000 for the last 24 hours. Meerkat will store data for a couple of minutes of the metric XYZ, but every 30 seconds it will poll Graphite only when it has received any data for the metric XYZ.
How we built Meerkat
I used what I know best: Python and beanstalkd, a simple but powerful queue server, to glue everything together. Meerkat consists of several components which are running as OS processes:
API. Built on top of Flask, the API stores the state of alerts. Every time an API call is performed, the data is saved to the DB.
Receiver. A simple Python HTTP server, that receives data from StatsD and puts it into the queue server.
Processor. This calculates the triggers. Every 30 seconds it reads alerts from disk. Then it consumes new metrics from the queue server. Then it calculates triggers by sending a request to the Graphite API for any encountered metrics. If anything has triggered then it puts a notification into the delivery queue.
Delivery. Consumes notification from the queue server and tries to deliver the thing to clients endpoint. If any problem occurs, it delays the next notification attempt.
As an exercise, I applied a functional style of programming to Meerkat. I did it for all the components except the API, which manages state. This helped a lot to reason about software and allowed me to structure the software such that it can be read like a book. For my taste, functional programs are also much easier to test.
All state is isolated in simple classes like Alert, Delivery, Manager with simple composition and they are used only in the API component.
Using the Meerkat API
Meerkat exposes its functionality via a RESTful API. The following is not a full documentation of the API but if gives you a rough idea how it works.
To add a new alert to Meerkat, you send the following request:
POST /v1/alerts/
{
"targets": [
"XYZ.001",
"XYZ.002"
],
"period": "30minutes",
"max_count": 100,
"delivery" : {
"endpoint": "amqp://username:password@rabbitmq_server:port/some_queue",
"timeout": "30minutes"
},
"meta" : {
"any field": "any value"
}
}
To get an alert:
GET /v1/alerts/<id>
To remove an alert:
DELETE /v1/alerts/<id>
To update an alert, you send a PUT request containing only the fields that have changed:
PUT /v1/alerts/<id>
{
"period": "10minute",
"max_count": 10
}
If an alert is triggered, you get a notification to the specified endpoint that contains this data:
{
"alert" : {
"id": 123213,
"targets": ["XYZ.001", "XYZ.002"],
"period": "1hour5minutes",
"max_count": 100,
"meta" : {"id": 1234}
},
"actual_count": {
"total": 108,
"metrics": {
"XYZ.001": 58,
"XYZ.002": 50
}
},
"triggered": 1387357839,
"postponed_until": 1387357899
}
Conclusions
This software still has to prove itself under production conditions. Early tests show however that it can achieve delays of below 30 seconds for alerts, which is good enough for our use case.
Also our experiments had shown that Graphite could handle a maximum of 950 requests/minute (rpm), and we estimated that the basic polling throttling would need much more requests than that. With the new Meerkat throttling we were able to reduce the load to a mean 260 rpm and mean deviation of 140 rpm.
This project taught me a couple of lessons:
- Hacking existing software is not the only way to go
- Building new things can be even more fun
- Functional programming and the queue server simplifies the data flow
- I enjoyed how fast I have built this software (thanks to Python and Flask)
As with every young software project, Meerkat has a number of areas where it can be improved e.g. caching of more data to reduce calls to Graphite, allowing low water mark.
After making our first experiences with Meerkat in production, we will decide how to take this project forward. Who knows, maybe we will even open source it.
Are you interested in Meerkat? Please let us know in the comments below.